
 Knowledge is a difficult concept to grasp. Once you think you have found a working definition, it slips away, like sand through your fingers. Why is it so important to define the concept of knowledge, or even consider it as an asset to the organisation? Reasons might not be as obvious as they might seem at first glance.
Knowledge is a difficult concept to grasp. Once you think you have found a working definition, it slips away, like sand through your fingers. Why is it so important to define the concept of knowledge, or even consider it as an asset to the organisation? Reasons might not be as obvious as they might seem at first glance.
In a modern organisation there is plenty of data. In a digital office environment the flow of data seems to be unstoppable. Logs generated by servers, excel sheets maintained by finance departments and the never ending flow of meeting minutes produced by eager clerks. Most data never becomes ‘information‘, the structured data that makes the sheer flow of letters and numbers meaningful. Instead it is doomed to live an archived life in the dungeons of someone’s cabinet or windowless basement.
Meaningful information, in turn, is always at risk of being volatile before it gets embedded in someone’s mind. Just before it forms a cocktail of information, combined with experience, where it can flourish in new combinations or even insights. This is where we approach ‘knowledge‘, as in the useful application of the right information at the right time, at the right place.

The data overload of many organisations is a commonly made mistake. The sheer flow of data, in case we need it some-day-for-some-reason, often paralyses the decision-making processes needed to run an organisation. There are simply too many sources of data for a human mind to digest, let alone comprehend. This is why we need to sort and filter. Serve data in digestible chunks that are meaningful in relation to each other. This seems to be quite a challenge, and frankly it is. Sorting and filtering data requires a goal in mind. An objective, even if the ultimate use of this information is not known (yet).
It is this bite size information that creates knowledge. Well, at least potentially. The seduction of analytics lurks in the shadows. From interesting correlations to astonishing eye-openers, all emerge from a sea of information in the shape of statistics. As the adage goes, there are small lies, big lies and there are statistics. They manifest themselves in someone saying: “did you know?…” and are never pretty. The unnuanced facts and figures of the analytic guru leave his audience in shock and awe. This is where doom scenarios are born, in that calculated mind of the guru and the feeble hearts in which the statistics find their home.
Who calls the guru naked? In every healthy organisation there has to be a point where statistics are being brought back to their merit. The simple naked truth that emerges from the numbers. The digestible pieces of data on which informed decisions can be made. In other words; what can we do to avoid the truth (whatever truth) to be defined by the construction of analytics instead of by the reality that we are trying to face?
It can’t be verification, as the analyst shows over and over again that new acquired data leads to the same conclusions. It’s like a lab experiment. The analyst controls the variables by selecting the data sources and the way these are processed. Any given outcome can be produced, ‘fabricated’ if you like. The outcome can and will be used to influence decisions. If it is not verification, then what can help us?
In the scientific tradition we have distanced ourselves from verification as a robust approach to establish the growth of knowledge. Instead the scientific community prescribes a couple of criteria to which information needs to adhere. It comes down to full transparency. Openness of source, approach and conclusions shall give the critical audience, endowed with opposing ideas or even agendas the opportunity to criticise the statistics brought forward. This does not mean that the presented statistics are wrong or manipulated by ‘less than sincere colleagues’, but it simply builds credibility of the numbers used as long as the presented statistics are not challenged by its critical audience. If challenged, and subsequently debated, the presented information might need to be revised or even ignored altogether. No matter what is changed or tweaked in the process, the information always gets richer in status, by revision or by standing the test of time. Both add to the credibility of the information and make the acceptance in people’s minds easier. It is the acceptance phase where knowledge emerges. Not in holding the truth, but in finding a shared set of ideas, experiences and approaches that lead to better decisions.
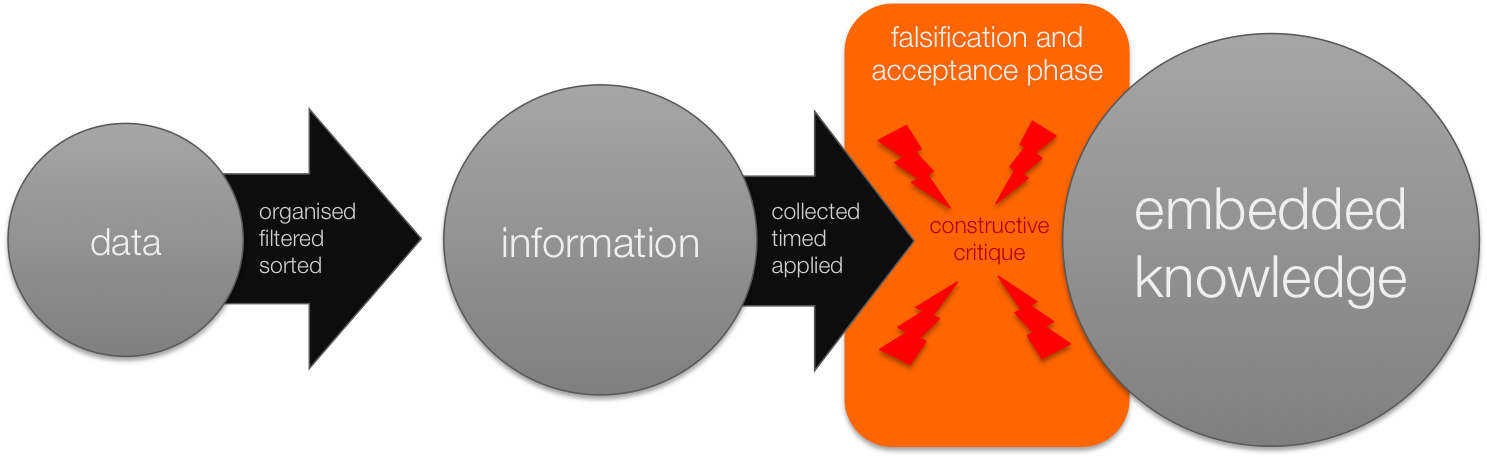
There is a risk in this approach. If the business community is not eager to endeavour on this path of falsification, this approach can easily lead to missattributed, yet unchallenged ‘knowledge’. It simply requires an active community to continuously challenge the presented information, or otherwise the information might lead to myths, unsound arguments and statistical fallacies. This is exactly the reason why transparency is key when presenting the information. It might even be the role of the modern day manager. Where he no longer has the in-depth expertise of his team members (if he ever had this at all), he simply needs to rely on the community of experts and stakeholders to falsify or support the output of his team. The manager’s goal should be to facilitate a transparent and digestible stream of information from his team members to their peers and customers. In this way he can satisfy both the falsification criteria and maintain the quality of work by making decisions on the basis of meaningful information.
So what can help to achieve this?
First and foremost there is a need to host the information. A wiki, a team room or a platforms alike. Basically it needs to adhere to a number of criteria:
- easily accessible
For the information to be read and understood is of course crucial to any form of constructive criticism. Ideally information is presented organically and relevant. Online platforms are by nature widely available as pc’s or smartphones are never far away. - centrally hosted
To publish, share and keep information up-to-date, it is important that all participants can access the latest version. Engaging in a (online) dialogue should not rely on portals being synchronised periodically. The user should always have access to the latest version. In fact one can argue that even the version tracking is not of utmost importance, as only the ‘current’ interpretation of data is relevant for the discussion to evolve. - ‘Open source’
This might be the most challenging element of the approach. For knowledge to evolve it is important that the participants feel comfortable with sharing their information even if it has not matured yet. In fact sharing drafts is part of the maturity process as it needs to be challenged at some point. As with many things, it’s better to turn half way then end up lost. It takes courage to expose thought experiments or even publically share a brainstorm. If the audience is aware of the draft character of the information, they will be willing to accept flaws in its rationale and even contribute by suggesting a (less flawed) alternative. If the information is openly available to adaptation by other participants the information becomes detached from the ‘initiator’. There is no concrete owner to the information that gets enhanced organically by the community. The information transcendents the initiator and becomes owned by the community. It becomes crowd-sourced.
To consolidate the objectives and requirements of the knowledge portal of the future, the following inventory can serve as a kick-off for further brainstorming.
Main question #1:
What is the objective of the portal?
- Broadcasting? (e.g. an intranet)
- File sharing? (e.g. team rooms or SharePoint)
- Collaboration? (e.g. Jives)
- Project management (e.g Basecamp)
All have unique requirements and are very difficult to combine or unite.
Main question #2:
What is the definition of success?
- X amount of content shared (archiving)
- Level of engagement (number of active users, contribution, collaboration, visits)
General guidelines:
- Content shall have identifiable owners
- Option to feedback should be omnipresent (directed at the information owners)
- Content shall be open source (editable) > compare Wikipedia
- Language used should be directed to the widest audience (no jargon or acronyms unless explained or linked to explanation)
- Users should be able to personalise home page to make relevant content easy accessible (compare iGoogle)
- Intuitive navigation is key (including a rich search engine)
- Content shall be available on the page itself (i.e. try to avoid linking to word, powerpoint or pdf documents unless they are explicitly, necessarily and only available in that format)
Common disadvantages of web based portals:
- The use of imagery is often not cut-and-paste
- The embedding of Powerpoint, Excel and other frequently used software drives adaptation (e.g. Slide Share)
A good interface has two goals:
- Find what you are looking for, and find it fast
- Be exposed to relevant information that you did not know you were looking for
A wide audience implies different levels of interaction:
Level 1: easy acceptance
intuitive interface, rich text editing, login required (need for identification and ownership of content) but should be seamless and effortless (SSO?)
Level 2: flexibility
more advanced users will be put of by constraints. Integration of spread sheets, free html and the use of imagery is key
Level 3: moderators
content management, organically growing navigation, themes/skins
Content was king…. and still is.
But Context defines success and adaptation.
Information shall be relevant in time, for particular users on an appropriate level (“know your audience, no matter how big and diverse”)
More information on the concept of falsification see Karl Popper (philosophy of science)